
Major Internet Issues Today
There has been a lot of noise in Canada on Twitter about the widespread network issues Shaw was experiencing, and also a lot of speculation about what the cause of those issues were. Simultaneously, the number of IPv4 routes advertised in the global routing table went over 512k, triggering memory overflows and crashes for some providers who had their heads in the sand about this problem that has been well known since 2007.
Shaw Problems
I downed BGP with Shaw around 10am this morning. Connectivity into Shaw without Shaw BGP up seemed better than on Shaw’s network itself. Epic Information Solutions turned up MTS Allstream BGP in place of Shaw around 4pm.
The Shaw issues were so widespread that The Register reported “Canadian ISP Shaw stumbles around internet with mystery ‘routing’ sickness”.
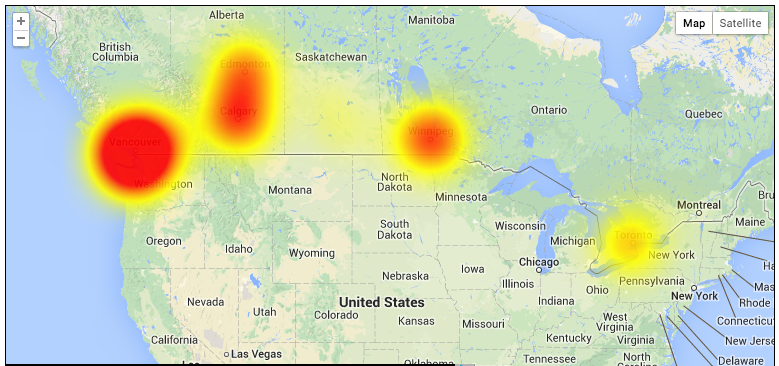
(from http://canadianoutages.com/status/shaw/map/)
BGP Routes/Updates
I don’t have a graph of the BGP updates from a Shaw peering session specifically, but I do have graphs for sessions with Hurricane Electric.
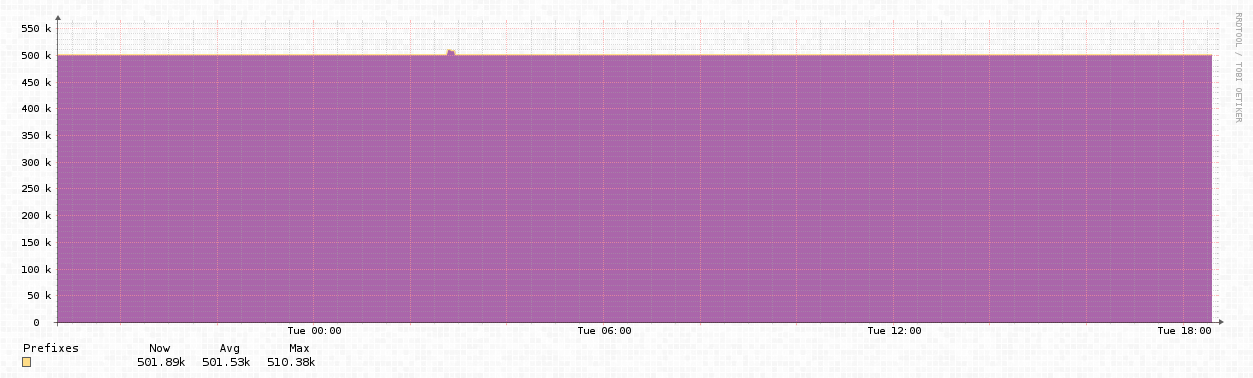
Global BGP Routes:
BGP Updates:
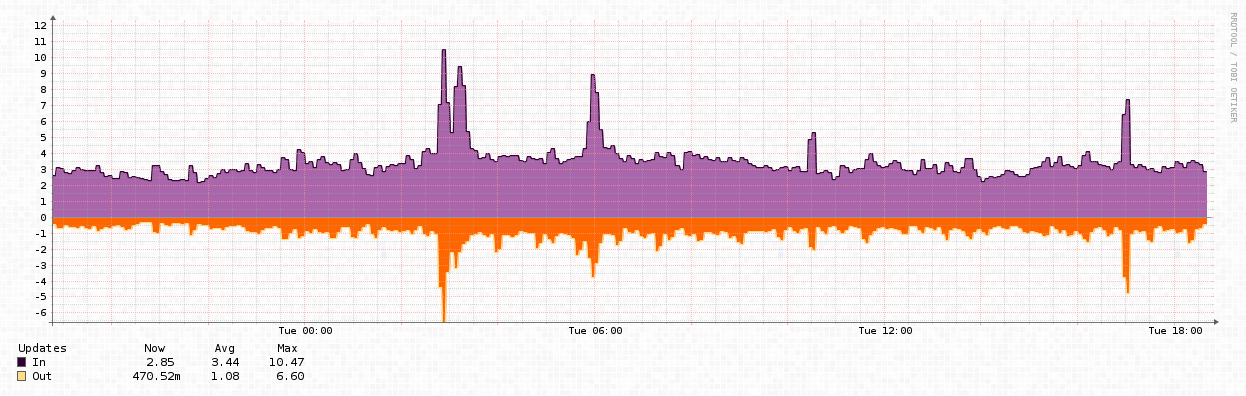
You can see the spike of updates around the time that the routes hit 510k (where I was monitoring at least). This caused some routers to crash, and generally not operate as intended. Prefixes were withdrawn, and came back, and there was a lot of churn in the global routing table at this time. The other spikes of updates were a result of emergency unscheduled/un-coordinated changes to reboot and increase limits by numerous providers with affected equipment.
Global Problems
A major US network with multiple ASNs (AS701 & AS705) had a network event which temporarily caused de-aggregation of their large prefixes, announcing more specific /24’s covering large chunks of their less-specific advertisements. Apparently this added approximately 15,000 new networks into the global BGP table for a short period of time. Peers of these networks could have received these announcements over un-filtered peering sessions, installing them into their own networks, and causing a domino effect of failures.
 | Theodore Baschak - Theo is a network engineer with experience operating core internet technologies like HTTP, HTTPS and DNS. He has extensive experience running service provider networks with OSPF, MPLS, and BGP. |